Data Lake Implementation using Microsoft Fabric
What is Microsoft Fabric?
Microsoft Fabric is an all-in-one analytics solution for enterprises that covers everything from data movement to data science, Real-Time Analytics, and business intelligence. It offers a comprehensive suite of services, including data lake, data engineering, and data integration, all in one place. There are several exciting capabilities that make working with Microsoft Fabric a thrilling experience, here are some:
- Complete Analytics Platform — We can perform almost all data-related tasks within a single platform.
- Lake-Centric and Open — All compute engines (Spark, T-SQL, KQL, Analysis Services) utilize a unified storage (Onelake) and standardized format (Delta-Parquet) for seamless integration.
- Reduced Data Movement — Data stored by one engine in Onelake is readily accessible by all other engines, eliminating the need for data movement.
- DirectLake Mode — Leveraging Power BI reports in DirectLake mode allows for real-time querying of Lakehouse data, eliminating the need for frequent refreshes.
Data Lake Architecture
In this example, we will explore the comprehensive creation of Lakehouse and Datawarehouse using the medallion architecture. Alternatively, we can focus solely on constructing a Lakehouse, which incorporates diverse data layers aligned with the medallion architecture. Creation of Datawarehouse brings few advantage like multi-table-transaction, TSQL capability, Store Procedures support etc. Here is the decision guide Datawarehouse vs Lakehouse.

The video below showcases a comprehensive demonstration of the use cases that we are going to discuss in this blogpost.
In the upcoming section, we will thoroughly examine each layer and meticulously delve into data integration, data engineering, data visualization.
Components used.
Microsoft Fabric provides multiple components to build different data solutions. We are going to use few of them to implement the above data lake architecture.
Data Engineering ( spark notebook)— Data Engineering provides spark enabled compute which helps us to create Delta table, Lakehouse and complex transformation
Data Factory ( pipeline) — Orchestration tool.
Data Warehouse — It fully separates compute from storage, enabling independent scaling of both the components. Additionally, it natively stores data in the open Delta Lake format.
OneLake : OneLake is a single data lake which comes with one Fabric-teannt/ organization. The I/O operation is optimized when we work with OneLake and Fabric Engines since we bypass the network latency since its native storage for the compute engines.
Power BI — Data Visualization tool.
Shortcuts — Shortcuts allow instant linking of data already existing in Azure and in other clouds, without any data duplication and movement, making OneLake a multi-cloud data lake.
Dataset — Power BI datasets represent a source of data that’s ready for reporting and visualization.
Raw layer
Raw layer stores the binary files from the open dataset( yellow Taxi Trip Records). In this use case, we have downloaded 144 files from 2011–2022. The files are kept in an ADLS Gen2 container and the same is attached to the Lakehouse as shortcut.
Also, you can copy the data from this given script. These sample data is readily available in a public storage account.
Raw Layer to Bronze Layer
The Spark notebook is used for transforming the downloaded data ( Raw Layer) into a standardized format (Bronze Layer) with the necessary data types. Additionally, we have included the “file_name” as an additional column in the file. The input data is read from the external ADLS Gen2, while the output files are written to the external ADLS Gen2 using shortcuts.
Notebook used : github link
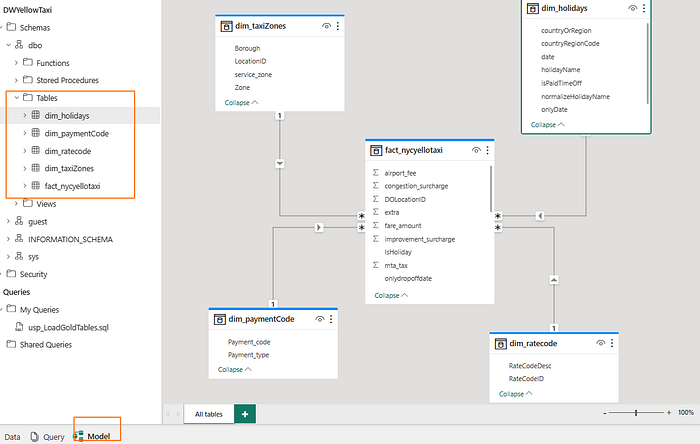
Bronze layer
In Bronze layer we have our binary files are ready for the ingestion. We got few more files for our reference data ingestion.
- Reference data( RateCode, Payment_type, taxi zones) are created from data dictionary. link to raw files.
- Reference data ( holiday) — We can use spark notebook to download the holiday data from the open dataset.
Bronze layer to Silver layer
Here Bronze layer is 144 parquet files, and Silver layer going to be a delta table. We can either use pipeline, or spark notebook to ingest the data. We are going to see both the option.
Option 1- using the pipeline
separate pipelines are created to move the trip data, and reference data. mainly the copy activity is being used to move the data.
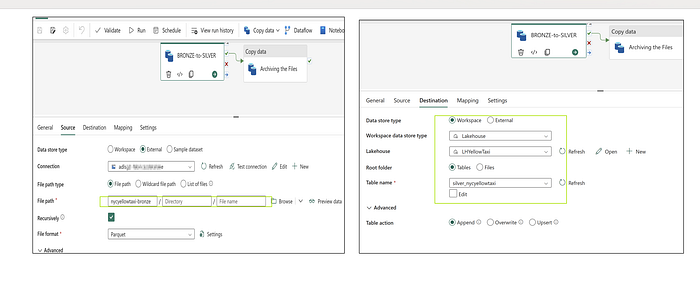
Option 2: using the spark notebook
By utilizing the Spark notebook, we can directly read the data from the attached storage shortcut and write it into a delta table. When writing the delta table in Fabric, there are several optimization techniques mentioned in this documentation that can be used.
spark.conf.set("sprk.sql.parquet.vorder.enabled", "true")
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", "true")
spark.conf.set("spark.microsoft.delta.optimizeWrite.binSize", "1073741824")
spark.conf.set("spark.sql.parquet.enableVectorizedReader","false")V-Order is a write time optimization to the parquet file format that enables lightning-fast reads under the Microsoft Fabric compute engines, such as Power BI, SQL, Spark and others. It uses special sorting, row group distribution, dictionary encoding and compression on parquet files.
Silver Layer
Within the Silver Layer, we store the data as delta tables. To store the data in table format, it is necessary to create a Lakehouse. Once the table is created, we can access it using tools such as Spark Notebook, Spark SQL, and the SQL endpoint.
What is Lakehouse sql endpoint? The Lakehouse SQL endpoint refers to a feature that allows us to analyze the data stored in the Lakehouse using the tsql language. It enables us to generate views, apply SQL securities, and perform read-only operations on the delta tables within the Lakehouse. However, it does not support DDL (Data Definition Language) or DML (Data Manipulation Language) operations related to the tables.
Upon loading the data, the tables become visible as depicted below. To successfully register a delta table as a table, it is imperative to maintain the data of the delta table in the /Tables/ location within the lakehouse.
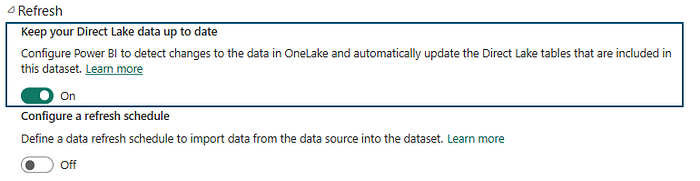
Power BI Dataset, DirectLake Reporting on Lakehouse Data
We can create the Power BI reports using the Lakehouse directly by creating a Dataset. DirectLake mode eliminates the import requirement by loading the data directly from OneLake. Unlike DirectQuery, there is no translation to other query languages or query execution on other database systems, yielding performance similar to import mode.

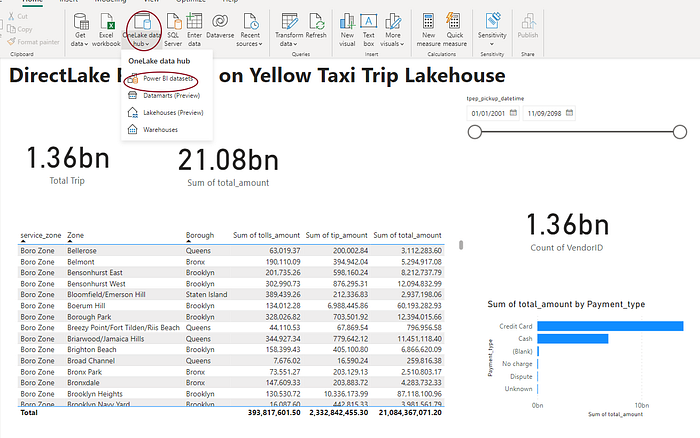
Silver Layer to Gold Layer
We are going to use store procedure here to move the data from Lakehouse to Warehouse. Before running the store procedure, make sure that Datawarehouse component is created in Fabric. Multi-table transaction is a crucial feature in Datawarehouses that ensures the “everything or none” loading capability. During the data transfer process from the lakehouse, we perform the final round of data cleansing to create the data model that aligns with our reporting requirements.
Gold layer
Post executing the store procedures, we can see the fact table and dimension tables in the Datawarehouse.
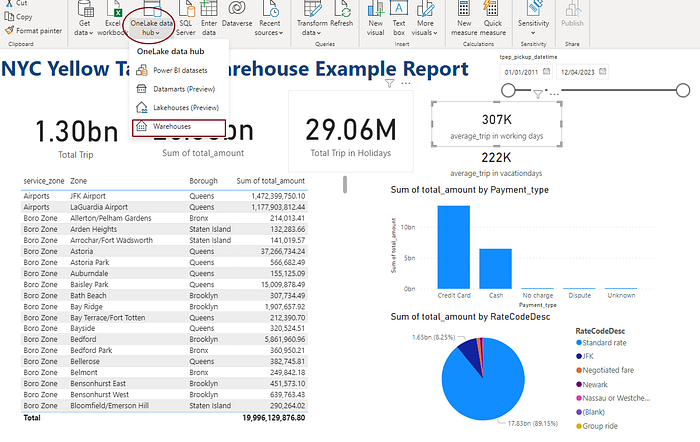
PBI Report
We can import the Model from the Power BI Desktop ( same or later June version), and start creating the report.
Hope this helps!
